
(FPT2025)Toward Domain-Aware Energy-Efficient Reconfigurable Architectures
研究背景与动机
当前,工业物联网、智能工厂、智慧医疗和自动驾驶等应用层出不穷,且都运行在边缘设备上。这些边缘设备通常由电池供电,功率预算非常有限。然而,这些应用却在不断演变,需求也在时刻变化。
为了满足这些应用对可重构性(Reconfigurability)和高能效(Energy Efficiency)的双重需求,我们需要设计灵活的硬件架构。
- ASIC 虽然能效高但缺乏灵活性,且非重复工程成本(NRE)高昂。
- FPGA 虽然灵活,但基于比特级的编程导致能效不如专用电路。
- 粗粒度可重构架构(CGRA) 则提供了一个极佳的中间选择。它由处理单元(PE)阵列组成,通过片上网络互连,支持字级编程,比FPGA更具能效优势。
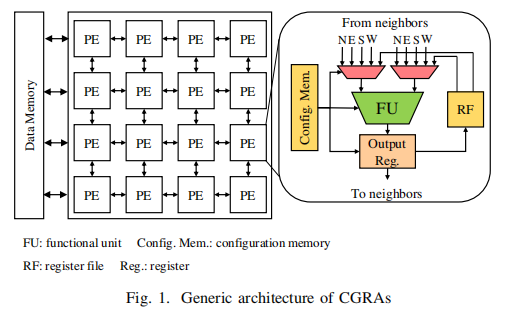
目前大多数 CGRA 采用同构(Homogeneous)设计,即所有 PE 支持相同的操作集。这种“一刀切”的设计会导致严重的功耗浪费,因为实际应用中的操作需求是不规则的。因此,我的研究重点是如何通过异构(Heterogeneous)设计,在不牺牲灵活性的前提下,利用领域感知(Domain-Aware)的特性来大幅降低功耗。
核心贡献一:DA-CGRA 架构生成流程
提出了一种利用编译器信息来设计领域特定 CGRA 的方法,称为 DA-CGRA。其生成流程如下: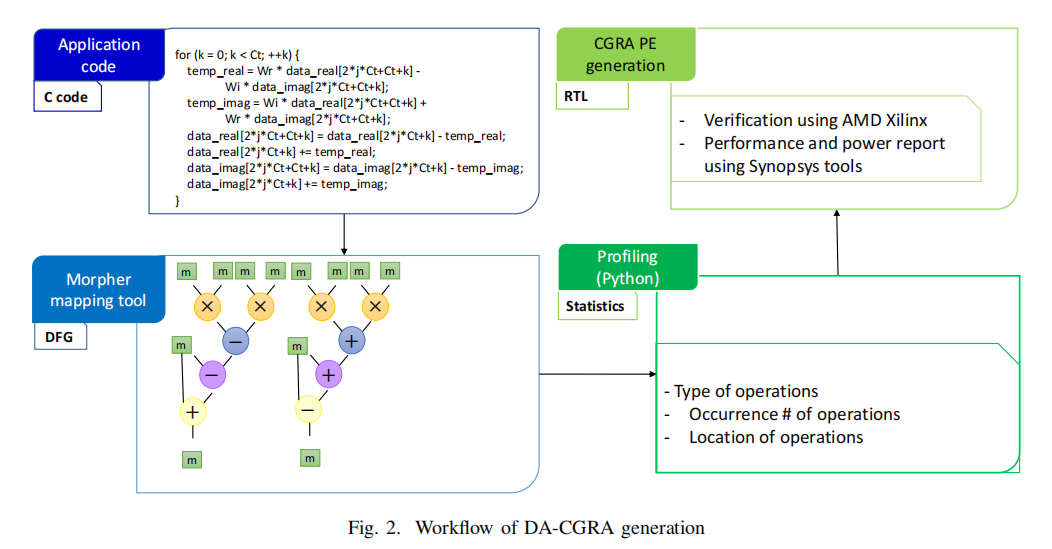
性能剖析(Profiling):
首先,我们从应用代码(如 C 代码)入手,使用 Morpher 工具生成数据流图(DFG)。接着,利用 Python 脚本对 DFG 进行深度剖析,提取关键信息,包括操作类型(加、减、乘等)、操作数量、内存访问模式以及循环展开因子。操作融合与PE提取:
在分析DFG时,我们发现乘法器的功耗远高于加/减法器(引入乘法会导致PE功耗增加约41%)。为了优化能效,我们在融合同一层级的操作时,避免强制所有PE都包含乘法器。最终,我们设计了三种定制化的PE:- ALU:功能最全,支持MAC、加减乘、移位和逻辑运算,主要用于复杂的地址生成(对应幻灯片中的红色PE)。
- RALU (Reduced ALU):仅支持乘法、加法和减法,用于核心计算。
- ADD/SUB:仅支持加法和减法,去掉了昂贵的乘法器。
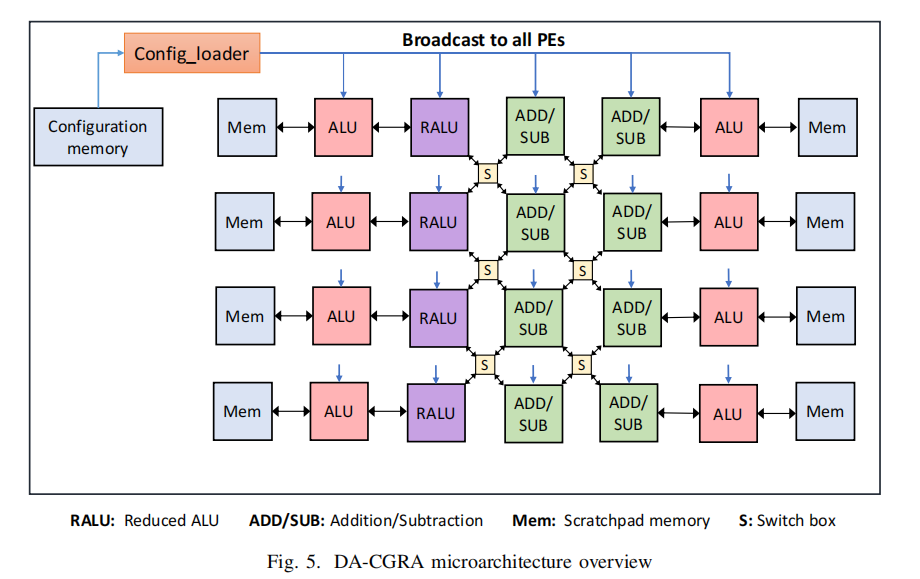
架构实现:
基于上述分析,我们生成了包含 4x5 PE 阵列 的异构架构,并在左右两侧配备了多组暂存器存储器(Scratchpad Memory)以支持数据和配置的快速存取。在互连方面,我们采用了8 端口交叉开关(Crossbar),虽然比 4 端口功耗稍高,但支持对角线传输,能显著减少启动间隔(II),从而将整体性能提升 3倍。
核心贡献二:系统级能效优化(SCISSORS 项目)
除了架构层面的 DA-CGRA,我还研究了系统级的能效优化技术,即 SCISSORS 项目。这项技术的核心是利用近阈值计算(Near-Threshold Computing)来降低电压,从而节省能耗。
挑战与解决方案:
降低电压会导致时序错误。为了解决这个问题,我们提出了一种基于算法的容错(ABFT)机制。以矩阵乘法为例,我们在硬件中加入了校验和(Checksum)计算逻辑动态电压调节:
系统在接收 DMA 数据后计算校验和。如果在计算结果中检测到错误(实际校验和与预期不符),系统会通过反馈机制通知电压调节器。我们在 Xilinx ZCU 102 FPGA 板上进行了验证,通过动态调整 PL 端(可编程逻辑端)的电压(VCCINT),找到“首次失效点”(Point of First Failure),使系统在保证精度的前提下运行在最低电压,从而最大化能效。
实验结果与对比评估
我们使用 Synopsys Design Compiler 在45nm 工艺下对 DA-CGRA 进行了综合,并与现有的先进 CGRA 架构进行了对比,包括同构的 HM-HyCUBE、ADRES,以及异构的 RipTide 和 FLEX。
- 能效优势: DA-CGRA的表现优于FLEX和RipTide。具体数据表明,在运行FFT应用时,DA-CGRA的能效比FLEX提高了 23%,比RipTide提高了 38%。
- 性能提升: 相比于性能最好的同构架构 HM-HyCUBE,DA-CGRA 实现了 3.2倍 的性能提升。
- 功耗分布: 由于我们精简了 PE 结构(去除了不必要的乘法器),大部分功耗被有效用于实际计算和数据存储,显著提升了整体效率。
总结与未来工作
论文作者博士工作通过架构级优化(领域感知异构设计)和电路/系统级技术(近阈值计算与容错)显著降低了可重构架构的能耗。未来,计划将进一步研究 CGRA 的设计空间探索(DSE)方法论。
问答环节还原与补充
问题 1:关于FPGA上的电压调节
- 提问:你在FPGA板上测试了这个系统,但我通过编程很难直接调整FPGA的电压,你是怎么做到的?
- 回答:是的,我们实际上使用了 PMBus 接口。通过I2C总线,我们可以控制板上的电压调节器。这是通过PS端(处理器系统)来完成的,我们编写了程序来动态调整VCCINT(内核电压)、VCCBRAM(块RAM电压)以及辅助电路的电压。我们可以单独调节,也可以一起调节,从而实现欠压测试。
问题 2:关于失效点与频率的关系
- 提问:在低频率下,失效点似乎向后移动了。你们测试过更低的频率吗?比如100MHz?
- 回答:我们测试了不同的频率。正如结果所示,在200MHz以下我们几乎没有观察到错误。当频率较高(如250MHz)时,错误会在较高的电压下就开始出现;而频率较低(如215MHz)时,我们可以在更低的电压下才观察到错误。这取决于加速器的关键路径延迟和我们设定的频率。
问题 3:关于Morpher工具的使用
- 提问:你在DFG生成过程中提到了Morpher工具,操作融合是自动完成的吗?
- 回答:Morpher主要用于生成数据流图(DFG)。至于操作融合和架构参数提取,是通过我们编写的 Python脚本 完成的。例如,脚本会识别DFG中用于地址生成的多个节点,并将它们合并,或者决定哪些加减法操作可以共用一个PE。这不是Morpher自带的功能,而是我们的贡献。
问题 4:关于开源计划
- 提问:你计划开源你的代码吗?
- 回答:目前我还在攻读博士学位,正在整理相关工作。在完成博士学位后,我计划将部分代码开源。
问题 5:关于互连网络的优化
- 提问:在架构生成中,针对互连网络(Interconnect)有没有做专门的优化?
- 回答:在互连方面,我们主要采用了 8端口交叉开关(8-output Crossbar)。虽然这比4端口更复杂,但鉴于我们采用了异构PE设计,我们需要更灵活的路由来保证数据流通,这能提供更高的并行度和旁路能力。所以目前的重点是灵活性,针对互连的深度定制优化在这一版中不是核心重点。